英伟达 LocateAnything:AI"看图找东西"慢,这个开源视觉定位模型把它提速了 10 倍
英伟达联合香港理工大学、南京大学推出开源视觉定位模型 LocateAnything,输入一张图加一句话,就能框出你要找的东西。 靠"一次画一个框"的并行解码新方法,它在单张顶级显卡上每秒能定位近 13 个目标,速度和精度同时领先同类模型,而且已经开源、免费下载。
现在的 AI 会聊天、会写代码、会画图,可有一件听起来很基础的事,它一直做得又慢又勉强:在一张图里,准确指出某样东西到底在哪。 这类任务在学术上叫"视觉定位"(visual grounding)。

这件事看着简单,却是机器人和"能帮你操作手机电脑的 AI"最容易卡住的地方。机器人要抓一个杯子,得先知道杯子在画面里的精确位置;AI 帮你点外卖,得先在截图里找到"立即下单"那个按钮。定位慢,整个动作就跟着卡。
LocateAnything 到底能做什么
视觉定位模型 LocateAnything 干的就是这件事:你给它一张图,再用一句话说出要找什么,它就把对应的位置用方框标出来。
它认的东西很杂:现实里的物体、手机屏幕上的按钮和图标、图片里的文字,都能定位。一个模型,把过去要好几个工具才能完成的活儿接了下来。
为什么能快这么多
关键在一个叫并行框解码的思路。
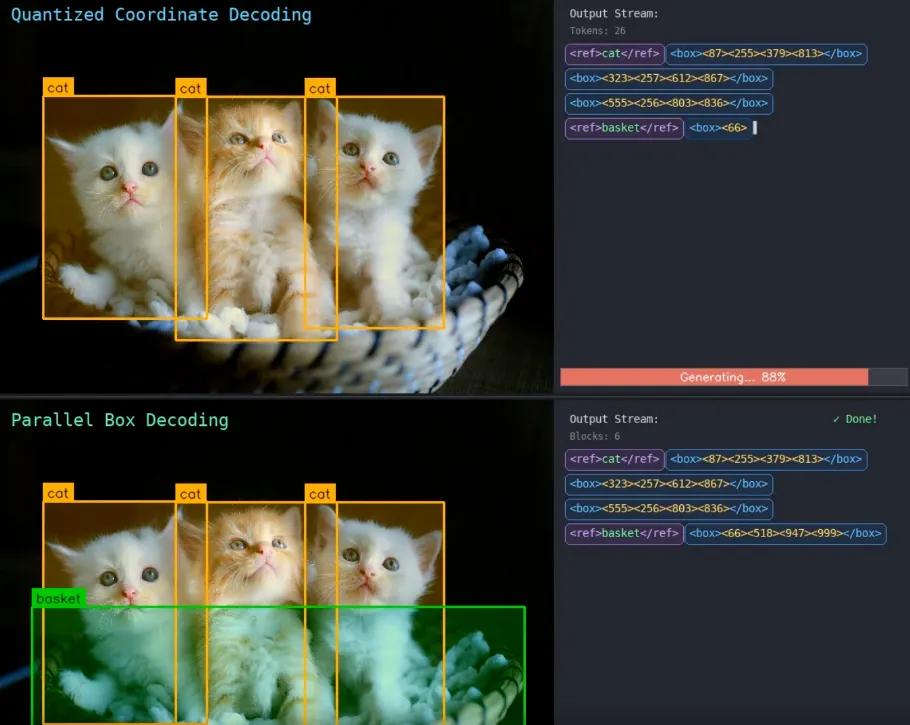
过去的 AI 报一个框的位置,像念身份证号一样,把四个坐标数字一个一个地念出来,慢,而且容易念错。LocateAnything 改成把一整个框当成一口气说完的整体,四个坐标同时给出。
它还准备了三种模式:追求速度的快速模式、追求精度的慢速模式,以及平时走快速、遇到难题自动切回慢速的混合模式。
成绩单
为了训练这个视觉定位模型,团队攒了一个超大数据集:1200 万张图片、1.38 亿条文字描述、7.85 亿个标注框。
速度上,同样一张 H100 显卡,它每秒能处理 12.7 个框,而拿来对照的两个同类模型,分别只有 1.1 个和 5.0 个。在最严格的定位精度评测里,它的得分也比对手高出一大截。
更要紧的是,这个模型已经公开放在网上,任何人都能免费下载使用。 对做机器人、做手机自动化工具的开发者来说,让 AI"看得快、指得准"的门槛,又降了一大截。
参考资料
相关报道
OpenAI 重启机器人团队:先帮工人盖楼,再让每个人都有一台人形机器人
做出 ChatGPT 和 Sora 的 OpenAI,正在悄悄招人重启机器人业务。 而这家公司五年前刚亲手关掉自己的机器人部门,说过机器人这条路走不通。
AI 复活逝者:和逝去的亲人再"见"一面,数字分身正在制造一种新的精神寄托
用逝者生前的聊天记录和语音,训练出一个能对话的"数字分身",国外把它叫做 deathbot 或 griefbot。有人靠这种 AI 复活服务疗愈,有人担心它让人走不出来。
全球每十台人形机器人九台中国造:中国人形机器人正成为下一个电动车级别的产业
中国人形机器人厂商宇树科技一家就拿下全球 **32.3%** 的份额。一台人形机器人的价格,两年里从豪华车跌到一部手机。