NVIDIA LocateAnything: An Open-Source Visual Grounding Model That Finds Objects in Images 10× Faster
NVIDIA, with Hong Kong Polytechnic University and Nanjing University, has released LocateAnything, an open-source visual grounding model: give it one image and one sentence, and it draws a box around whatever you asked for. Thanks to a new "draw the whole box at once" parallel-decoding method, it locates nearly 13 targets per second on a single top-end GPU — outpacing comparable models on both speed and accuracy — and it's free to download.
Today's AI can hold a conversation, write code, and generate images. Yet one task that sounds almost trivial has stayed slow and clumsy: pointing precisely to where a given object sits inside an image. In the research world, this is called visual grounding.

It looks simple, but it's exactly where robots and "AI that operates your phone or computer for you" tend to choke. A robot reaching for a cup first needs the cup's precise location in the frame; an AI placing your takeout order first has to find the "Order Now" button in a screenshot. Slow localization stalls the entire chain of action.
What LocateAnything actually does
The visual grounding model LocateAnything does precisely this: hand it an image, describe in one sentence what you're looking for, and it marks the matching spot with a bounding box.
The range of things it can recognize is broad — real-world objects, buttons and icons on a phone screen, even text printed inside a picture. One model now handles work that used to require several separate tools.
Why it's so much faster
The key is a technique the team calls parallel box decoding.
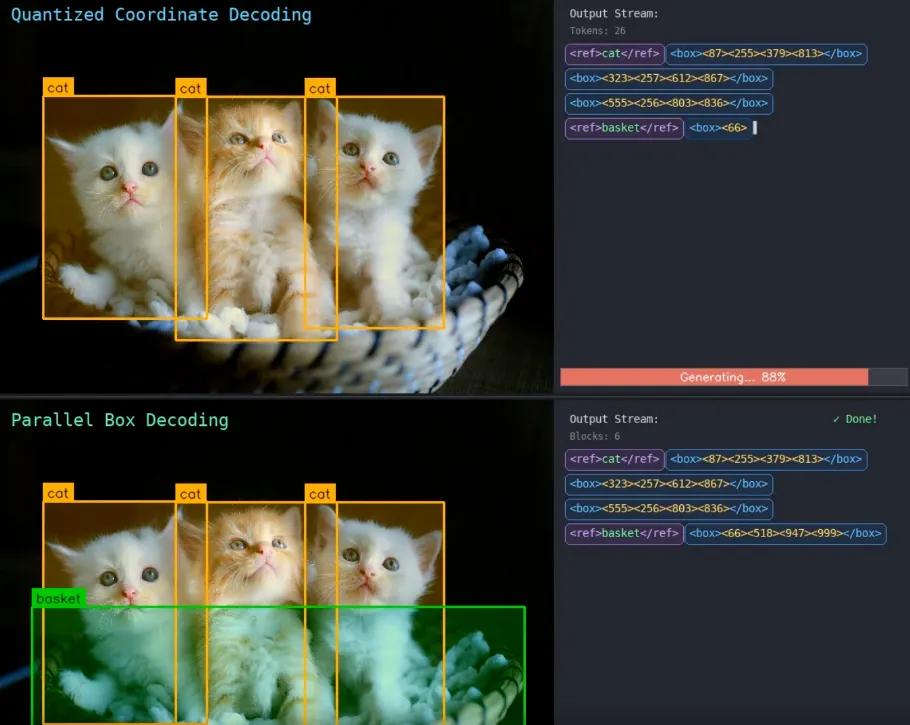
Older models report a box's position the way you'd read out a long ID number — emitting the four coordinates one digit at a time, slowly and with plenty of room for error. LocateAnything instead treats an entire box as something said in a single breath, producing all four coordinates at once.
It also ships with three modes: a fast mode tuned for speed, a slow mode tuned for precision, and a hybrid mode that runs fast by default and automatically falls back to slow on the hard cases.
The benchmark scorecard
To train the model, the team assembled a massive dataset: 12 million images, 138 million text descriptions, and 785 million annotated boxes.
On speed, running on the same H100 GPU, it processes 12.7 boxes per second — versus 1.1 and 5.0 for the two comparable models used as baselines. On the strictest localization-accuracy benchmark, its score beats those rivals by a wide margin as well.
More importantly, the model is already public and free for anyone to download and use. For developers building robots or phone-automation tools, the bar for getting AI to "see fast and point accurately" just dropped a long way.
References
Related
AI Surveillance Cameras That Spot Someone About to Jump — and Have Already Saved Two Lives in Japan
Tokyo startup Asilla has bolted behavior-recognition AI onto ordinary surveillance cameras, training it to flag people who pace at a platform edge or linger by a rooftop railing and alert security the moment something looks wrong. The AI video-analytics system was trained on roughly 7 million clips and now runs across about 40 stations and malls in Tokyo and Kanagawa, where it has already intercepted at least two people.
AI Voice Cloning Can Fake Your Family in Seconds — Here's the One Safe Word That Beats the Scam
Americans lost roughly $890 million to AI-related fraud last year, and AI voice-cloning scams are the fastest-growing slice of it. A few seconds of audio is all a scammer needs to clone a loved one's voice — and the FBI and experts admit even they can no longer reliably tell real from fake. Instead of trusting your own ears, lock in a few fixed defenses — starting with a family "safe word."
OpenAI Reboots Its Robotics Team: First to Help Build the World, Then a Personal Robot for Everyone
The company behind ChatGPT and Sora is quietly hiring its way back into robotics. Five years ago, OpenAI shut down its own robotics division and called the path a dead end.